




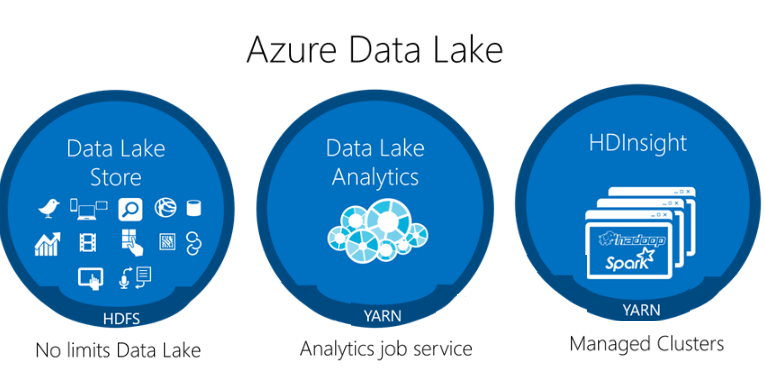
There are so many buzzwords these days regarding data management, ranging from database and data warehouse to data lakes. It has become really essential to understand the difference between these two concepts if one wants to explore and experiment in the field of data science. A data lake is a storage repository that can store large amounts of semi-structured and unstructured data.
It acts as a place that can store every type of data in its native format with no fixed limits on account size or type of file. It also offers high data quantity to increase analytical performance and native integration. Data lake can be described as a large container which is very similar to real lakes and rivers, hence the term.
Just like a lake has multiple tributaries coming in, a data lake has structured data, unstructured data, machine to machine and logs flowing in real-time. Data Lake aims to store all this data in a cost-effective and user friendly way to access this for future use. Unlike the hierarchical structure of the traditional data warehouse, the data lakes have a flat architecture.
Every data element in a data lake is given a unique identifier and tagged with a set of metadata information. On the other hand, a data warehouse is a model to support the flow of data from operational systems to decision systems. It basically provides a place to analyse all the data.
Key Data lake concepts are-
- Security
- Data governance
- Team work
- Data quality
- Data discovery
- Data auditing
- Data storage
- Data lineage
- Data exploration
- Data ingestion
Thoughtstorm undertakes the complex task of data analysis using the concepts of data lakes and data warehouse, as need be. Our systematic and efficient approaches help us in the same.


